* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] 아웃라이어 제거하는 방법
By MK on January 10, 2019
표준화 변환시에는 “이상치, 특이값 (outlier)이 없어야 한다” 는 가정사항이 있다. 표준정규분포로 변환하는 공식이 z = (x - 평균)/표준편차 이며, 평균(mean)은 이상치, 특이값에 엄청 민감 하기 때문이다.
스케일 전 아웃라이어를 제거해야하는 당위성은 아래 링크를 통해 살펴 볼 수 있다.
[이전 포스팅] 스케일러 종류 및 특징 보러가기
일반적으로 6시그마, 즉 플러스/마이너스 3표준편차에 해당된느 값을 아웃라이어로 보고 제거하는 방법이 있으며, 모델링 스케일링 처리를 할때 RoubustScaler를 사용하는 방법도 있다.
이밖에도 sklearn 패키지를 통해 문제를 해결할 수 있다.
1. Standard 대신 Roubust 사용하기
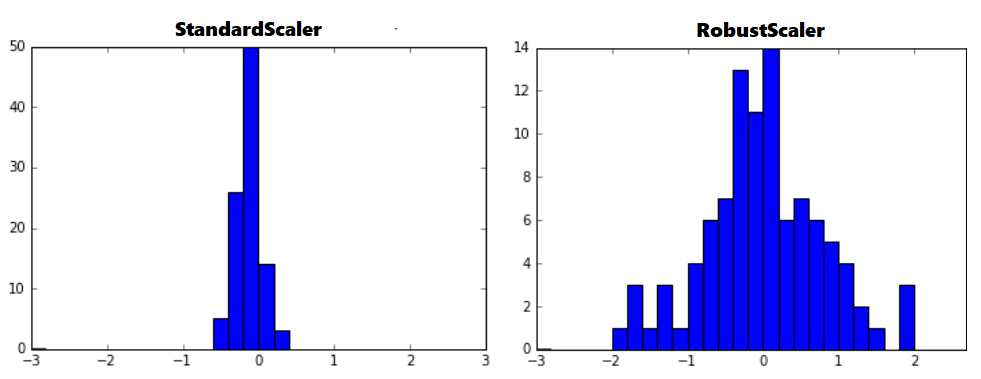
아웃라이어의 영향을 최소화한 기법이다. 중앙값(median)과 IQR(interquartile range)을 사용하기 때문에 StandardScaler와 비교해보면 표준화 후 동일한 값을 더 넓게 분포 시키고 있음을 확인 할 수 있다.
IQR = Q3 - Q1 : 즉, 25퍼센타일과 75퍼센타일의 값들을 다룬다.
아웃라이어를 포함하는 데이터의 표준화 결과는 아래와 같다.
from sklearn.preprocessing import RobustScaler
robustScaler = RobustScaler()
print(robustScaler.fit(train_data))
train_data_robustScaled = robustScaler.transform(train_data)
2. sklearn 패키지 활용
크게 2가지로 분류하고 4가지 방법론이 있다.
첫째, novelty detection 새로운 값이 들어왔을 때, 그 값이 기존의 분포에 적합한 값인지 아닌지를 구별해 내는 방법
둘째, outlier detection 현재 가지고 있는 값들 중에서 이상치를 판별해는 방법
그 종류는 다음과 같다.
| 종류 | 구분 | |
|---|---|---|
| 1 | One-class SVM | Novelty |
| 2 | Fitting an elliptic envelope | Outlier |
| 3 | Isolation Forest | Outlier |
| 4 | Local Outlier Factor | Outlier |
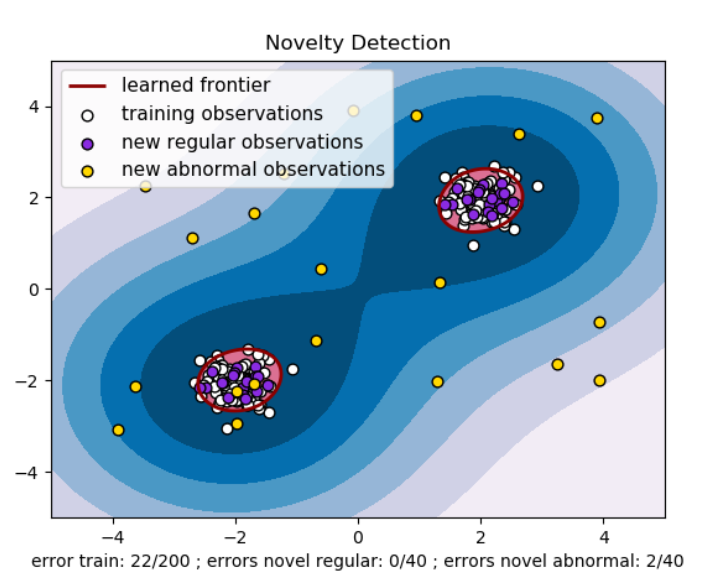
One-class SVM
Novelty를 위한 방법론으로 처음 관측 분포의 윤곽선을 새로운 차원 공간에 그려 놓고 추가 관측치가 경계로부터 구분된 공간 내에 있으면 초기 관측치와 같은 집단, 그렇지 않으면 비정상 데이터라고 간주한다.
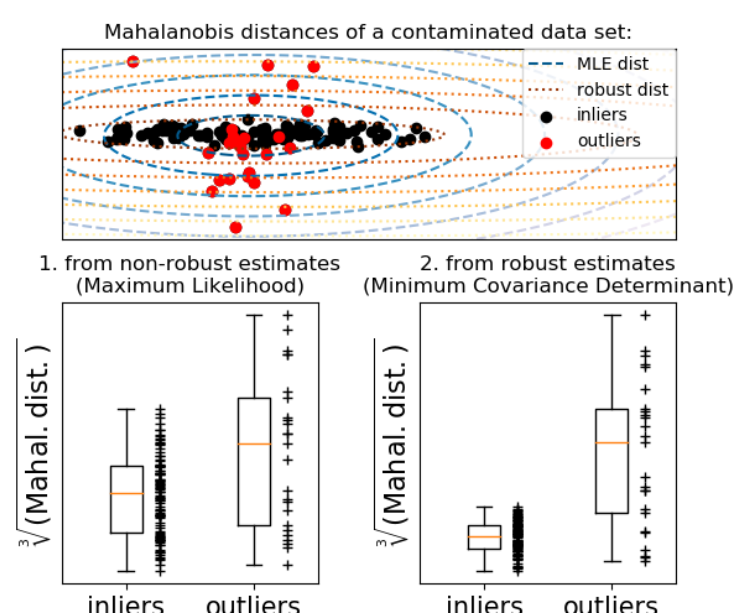
Fitting an elliptic envelope
이 방법론은 데이터 분포에 대한 가정이 필요하다. inlier 데이터가 가우스 분포라고 가정하면 inlie 위치 및 공분산을 추정할 수 있다. 이렇게 얻은 Mahalanobis distances는 외도 측정을 유도하는데 사용한다.
Scikit-learn은 객체 공분산을 제공한다. 강력한 공분산 추정치를 데이터에 적용하여 타원을 중앙 데이터 포인트에 맞춰 중앙 모드 외부의 점을 무시하는 방법으로 Outlier를 제거할 수 있다.
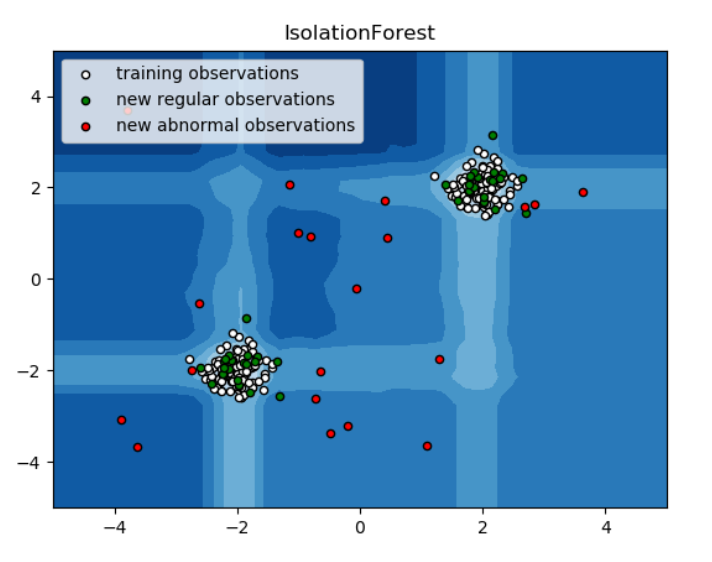
Isolation Forest
다차원 데이터셋에서 효율적으로 작동하는 아웃라이어 제거 방법이다. Isolation Forest는 랜덤하게 선택된 Feature의 MinMax값을 랜덤하게 분리한 관측치들로 구성된다.
재귀 분할은 트리 구조로 나타낼 수 있으므로 샘플을 분리하는 데 필요한 분할 수는 루트 노드에서 종결 노드까지의 경로 길이와 동일하다.
이러한 무작위 Forest에 대해 평균된이 경로 길이는 정규성과 결정의 척도가 된다.
이상치에 대한 무작위 분할을 그 경로가 현저하게 짧아진다. 따라서 특정 샘플에 대해 더 짧은 경로 길이를 생성할 때 아웃라이어일 가능성이 높다.
# Isolation Forest 방법을 사용하기 위해, 변수로 선언을 해 준다.
clf = IsolationForest(max_samples=1000, random_state=1)
# fit 함수를 이용하여, 데이터셋을 학습시킨다. race_for_out은 dataframe의 이름이다.
clf.fit(race_for_out)
# predict 함수를 이용하여, outlier를 판별해 준다. 0과 1로 이루어진 Series형태의 데이터가 나온다.
y_pred_outliers = clf.predict(race_for_out)
# 원래의 dataframe에 붙이기. 데이터가 0인 것이 outlier이기 때문에, 0인 것을 제거하면 outlier가 제거된 dataframe을 얻을 수 있다.
out = pd.DataFrame(y_pred_outliers)
out = out.rename(columns={0: "out"})
race_an1 = pd.concat([race_for_out, out], 1)
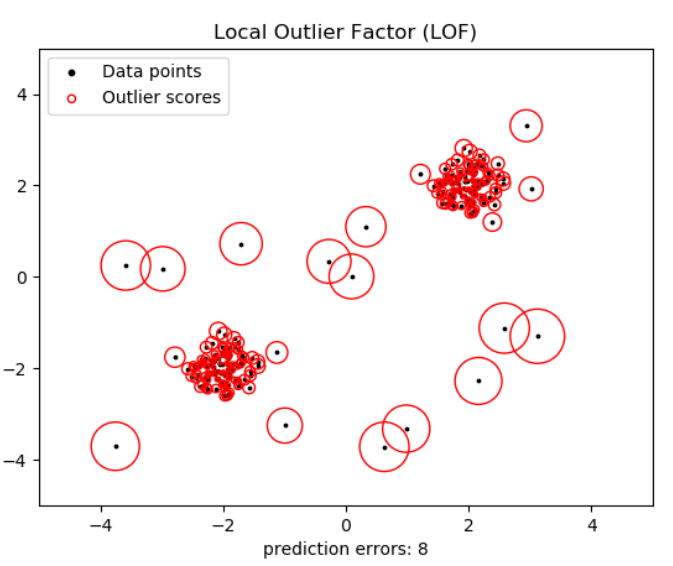
Local Outlier Factor
이 방법 역시 다차원 데이터의 아웃라이어 제거에 효과적이다.
알고리즘은 관측치의 비정상적인 정도를 반영하는 점수(로컬 아웃 라이어 계수)를 계산한다.
주어진 데이터 포인트의 이웃에 대한 로컬 밀도 편차를 측정한 후 이웃들보다 밀도가 훨씬 낮은 샘플을 감지하는 것이다.
실제로, 국부 밀도는 가장 가까운 k개의 이웃으로부터 얻어진다. 정상적인 인스턴스는 이웃과 유사한 로컬 밀도를 가질 것으로 예상되지만, 비정상적인 데이터는 훨씬 더 작은 국소 밀도를 가질 것으로 예상된다.
LOF 알고리즘의 강점은 데이터 세트의 로컬 및 전역 속성을 모두 고려한다는 것이다. 비정상 샘플의 기본 밀도가 다른 데이터 세트에서도 성능이 뛰어나다. 표본이 얼마나 고립되어 있는가가 아니라 주위의 이웃에 대해 얼마나 고립되어 있는지를 판단하는 것이다.
Reference
https://tariat.tistory.com/29
https://scikit-learn.org/stable/modules/outlier_detection.html
