* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] SMOTE를 통한 데이터 불균형 처리
By MK on January 4, 2019
데이터 분석시 쉽게 마주하게 되는 문제 중 하나가 데이터의 불균형이다.
우리가 찾고자하는 데이터의 타겟의 수가 매우 극소수인 케이스가 많다.
예를 들어 부도예측시 부도는 전체 기업의 3% 내외로 극소수이다.
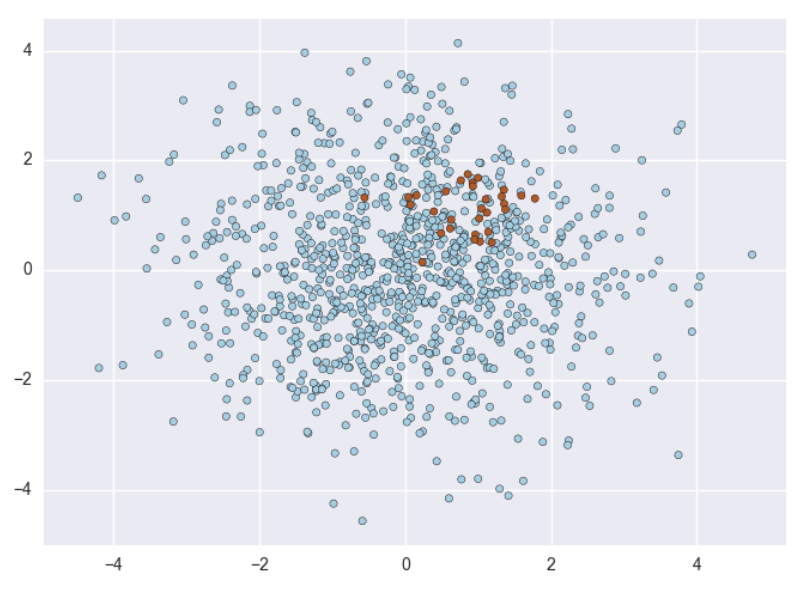
이러한 비대칭 데이터셋에서는 정확도(accuracy)가 높아도 재현율(recall, 실제 부실을 부실이라고 예측할 확률)이 급격히 작아지는 현상이 발생하게 된다.
100개의 데이터 중 3개가 부실이면, 모두 정상이라고 예측해도 정확도가 97%가 나오기 때문이다.
데이터 불균형 처리 방법
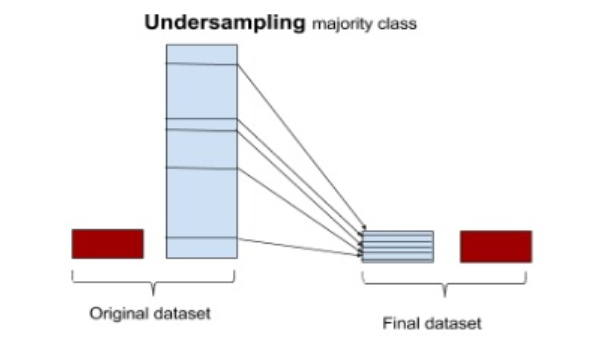
언더샘플링
1. 무작위추출 : 무작위로 정상 데이터를 일부만 선택
2. 유의정보 : 유의한 데이터만을 남기는 방식(알고리즘 : EasyEnsemble, BalanceCascade)
언더샘플링의 경우 데이터의 소실이 매우 크고, 때로는 중요한 정상데이터를 잃게 될 수 있다.
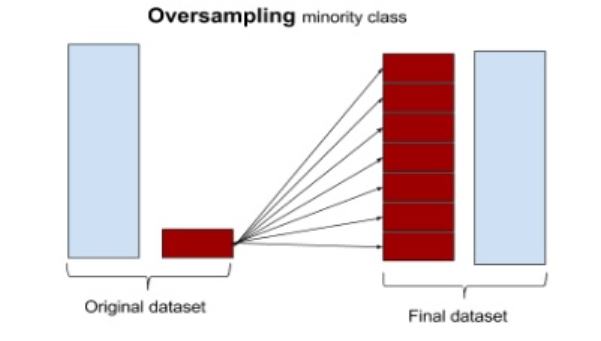
오버샘플링
1. 무작위추출 : 무작위로 소수 데이터를 복제
2. 유의정보 : 사전에 기준을 정해서 소수 데이터를 복제
정보가 손실되지 않는다는 장점이 있으나, 복제된 관측치를 원래 데이터 세트에 추가하기 만하면 여러 유형의 관측치를 다수 추가하여 오버 피팅 (overfitting)을 초래할 수 있다.
이러한 경우 trainset의 성능은 높으나 testset의 성능은 나빠질 수 있다.
3. 합성 데이터 생성 : 소수 데이터를 단순 복제하는 것이 아니라 새로운 복제본을 만들어 낸다.
비용 민감 학습(Cost Sensitive Learning,CSL)
오분류하는 행위를 비용으로 측정한다.
Total Cost = C(FN)xFN + C(FP)xFP
FN은 잘못 예측 된 긍정적인 관찰의 수
FP는 잘못 예측 된 부정적 사례의 수
C(FN)과 C(FP)는 False Negative 및 False Positive와 관련된 비용과 각각 일치한다. C(FN)> C(FP)잘못 분류된 비용을 설명하는 비용 매트릭스를 사용하여 불균형 학습 문제를 해결한다.
최근의 이 방법론은 샘플링 기법으로의 대체로 대두되기도 한다.
실무에서는 어떤 방법을 많이 사용할까?
데이터의 특성이나 확보 데이터량에 따라 다르겠지만, 딥러닝 분석을 위해서는 많은 데이터 확보가 효과적이므로 오버샘플링 기법을 적용하는게 좋다.
SMOTE알고리즘은 오버샘플링 기법 중 합성데이터를 생성하는 방식으로 가장 많이 사용되고 있는 모델이다.
SMOTE(synthetic minority oversampling technique)란, 합성 소수 샘플링 기술로 다수 클래스를 샘플링하고 기존 소수 샘플을 보간하여 새로운 소수 인스턴스를 합성해낸다.
일반적인 경우 성공적으로 작동하지만, 소수데이터들 사이를 보간하여 작동하기 때문에 모델링셋의 소수데이터들 사이의 특성만을 반영하고 새로운 사례의 데이터 예측엔 취약할 수 있다.
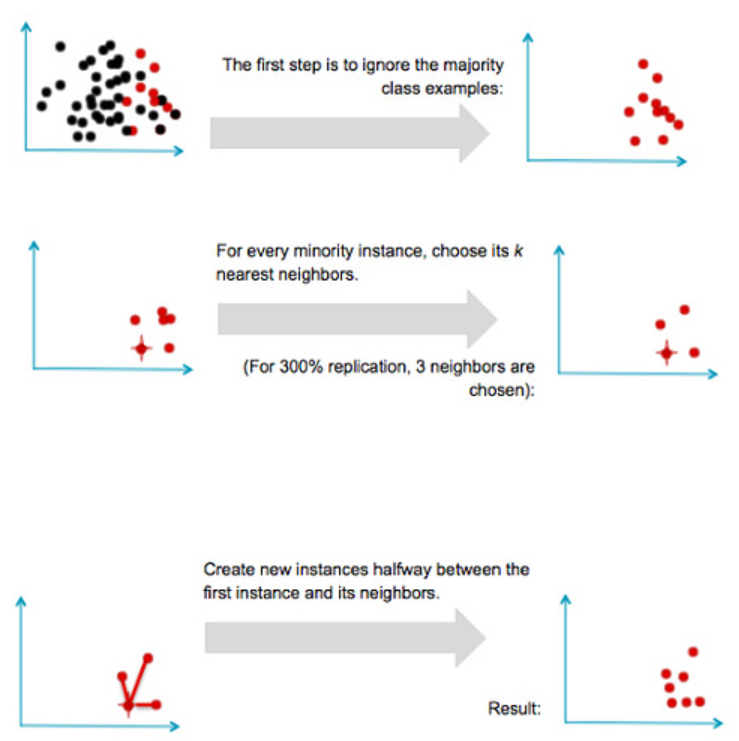
SMOTE 동작 방식
부트스트래핑이나 KNN(최근접이웃) 모델 기법을 활용한다.
소수 데이터 중 특정 벡터 (샘플)와 가장 가까운 이웃 사이의 차이를 계산한다.
이 차이에 0과 1사이의 난수를 곱한다.
타겟 벡터에 추가한다.
두 개의 특정 기능 사이의 선분을 따라 임의의 점을 선택할 수 있다.
파이썬 코드
데이터 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit_transform(X_train)
X_train = scaler.fit_transform(X_train)
데이터 복제
from sklearn.datasets import make_classification
from sklearn.decomposition import PCA
from imblearn.over_sampling import SMOTE
# 모델설정
sm = SMOTE(ratio='auto', kind='regular')
# train데이터를 넣어 복제함
X_resampled, y_resampled = sm.fit_sample(X_train,list(y_train))
print('After OverSampling, the shape of train_X: {}'.format(X_resampled.shape))
print('After OverSampling, the shape of train_y: {} \n'.format(X_resampled.shape))
print("After OverSampling, counts of label '1': {}".format(sum(y_resampled==1)))
print("After OverSampling, counts of label '0': {}".format(sum(y_resampled==0)))

정상데이터수를 기준으로 50% : 50%로 소수데이터가 합성 생성된다.
X_resampled.shape, y_resampled.shape
Reference
- https://www.analyticsvidhya.com/blog/2016/03/practical-guide-deal-imbalanced-classification-problems/
- https://www.svds.com/learning-imbalanced-classes/
- https://datascienceschool.net/view-notebook/c1a8dad913f74811ae8eef5d3bedc0c3/
- http://goodtogreate.tistory.com/entry/Handling-Class-Imbalance-with-R-and-Caret-An-introduction
