* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] 변수중요도(Feature Importances) 추출
By MK on January 4, 2019
1. 모델 가져오기
먼저 나무유형 머신러닝 모델이 필요하다. 작업 후 pickle 변수 저장 후 사용하였다.
[저장하기 코드 참고]
import pickle
pickle.dump(models, open('./models/models.pkl','wb'))
[가져오기 코드 참고]
with open('./models/models.pkl', 'rb') as file:
models = pickle.load(file)
해당 변수에는 ‘random forest’라는 이름의 나무유형 모델이 저장되어 있다.
2. 변수별 중요도 추출
변수 중요도 반환 함수 생성
def feature_impt(model_nm, x, y):
model = models[model_nm]
model = model.fit(x, y)
return model.feature_importances_
rf_impt = feature_impt('random forest',x_train, y_train)
3. 랭킹 및 그래프 그리기
그래프 함수 생성
def graph_generator(model,importances, X):
std = np.std([tree.feature_importances_ for tree in model.estimators_],
axis=0)
indices = np.argsort(importances)[::-1]
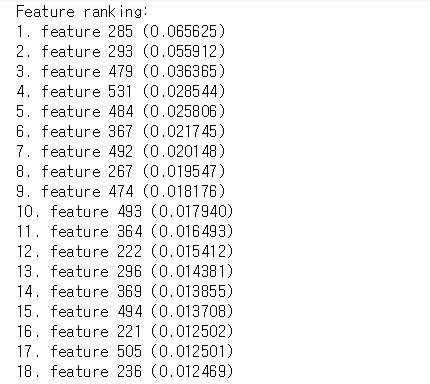
# Print the feature ranking
print("Feature ranking:")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
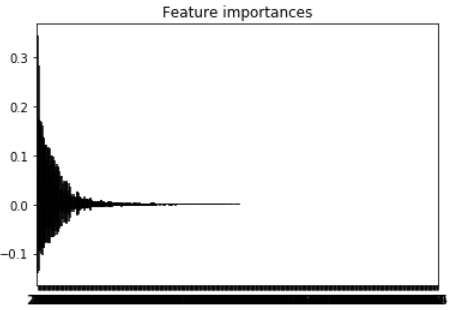
# Plot the feature importances of the forest
plt.figure()
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices],
color="r", yerr=std[indices], align="center")
plt.xticks(range(X.shape[1]), indices)
plt.xlim([-1, X.shape[1]])
plt.show()
graph_generator(models['random forest'], rf_impt, x_train)