* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] Pearson 상관관계 파악
By MK on January 2, 2019
데이터 모델링시, 변수선정시 결정적인 변수가 포함되어있지는 않은지 확인할 필요가 있다. 예를 들어 Label값과 거의 일치하는 변수가 포함되어 있을 경우, 성능은 당연히 높아질 수 밖에 없으나 모델로써의 가치는 떨어지게 된다.
사전에 label과 변수간 1:1 상관관계를 파악해보자.
일반적으로 다변량통계분석에선 공분산성을 필수적으로 파악하지만 딥러닝 모델링시에는 의견이 분분하다. 경험상 딥러닝을 설계할 경우 가중치가 다양한 조합의 영향을 받아 형성되어 변수의 공분산성을 임의로 제거할 필요가 없어보이는 듯했다.
통계분석에서는 최적의 최소한의 변수집합으로 구성하는것이 best였으나 딥러닝에서는 변수 항목을 많이 늘릴수록 성능이 높아지는 이유도 이와 연관이 있다.
다만, 이와 무관하게 1차적으로 label과 변수들간 상관관계를 파악해보는 것은 유용할 것이다.
1. 데이터 설명
x_train에는 순수 변수항목들의 값이, y_train에는 ‘0’,’1’로 표현된 label값이 들어있다.
데이터는 모델에 적용되기 전 데이터, 즉 전처리 후 데이터를 사용하였다.
만약 array 값이라면 데이터프레임으로 변환한 후 사용한다.
x_train = pd.DataFrame(x_train)
y_train = pd.DataFrame(y_train)
2. 상관계수 구하기
상관계수를 구하는 일은 코드 몇줄이면 된다.
corrs = []
length = data.shape[1]
for i in range(0,length): # 라벨은 제외 1부터 시작
# 라벨과 각 데이터 변수 합치기
corr_data = pd.concat([y_train, x_train[[i]]], axis=1)
# 상관관계 계산
if i > 0: # 0은 라벨과 라벨의 상관관계이므로 1부터 계산한다.
temp_corr = corr_data.corr().iloc[1][0]
corrs.append(temp_corr)
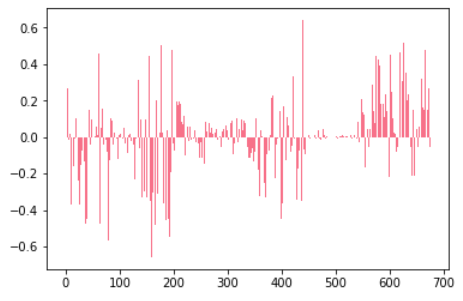
3. 결과 확인하기
샘플결과 확인
corr_data = pd.concat([y_train, x_train[[5]]], axis=1)
corr_data.corr().iloc[1][0]
0.08738988043206865
최대, 최소값 확인
min(corrs),max(corrs)
(-0.6586983548116356, 0.6407439595985603)
그래프 그리기
plt.bar(range(0,length),corrs, align='center')
plt.show()