* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] DNN 모델링시 학습곡선 체크하기
By MK on December 28, 2018
같은 데이터에 같은 모델을 적용하더라도 설계를 얼마나 잘하느냐에 따라 결과가 매우 달라진다. 설계를 할때 아래와 같은 주요변수(요인)들이 있다.
- Batchsize
한번에 학습할 데이터량을 결정한다.
클수록 한번 볼때 크게 보는 효과가 있다. 너무 크면 일반화 능력(과적합 우려)이 떨어질 수 있으므로 유의해야 한다.
- Epochs
데이터가 학습하는 반복 횟수이다. epochs 조절을 통해 과적합을 조절할수도 있다.
너무 성능이 높아 과적합이 우려될 경우 적당선에서 학습을 멈춘다.
- Layer design
데이터에 따라 설계는 적정한 구성을 찾아야 한다.
정답은 없고 학습곡선을 확인해가며 loss를 잘 체크한다.
test한 데이터셋 기준으로는 input nodes와 유사한 크기의 dense로 시작하여 점차 줄여나간 경우 성능이 좋았다.
- Batchnormal
과적합을 방지하기 위해 dropout과 사용하기도 하지만 실제로는 weight 값들이 학습하기 좋은 범위의 숫자로 매칭될수 있도록 하는 역할을 하기 위해 Activaion함수 앞에서 사용된다.
batchnormal을 써서 성능이 좋아지는 경우도 있으나 testset의 경우 성능이 더 떨어지기도 했다. 즉 다른 조합들과 데이터셋에 따라 달라진다.
- Dropout
과적합 방지용으로 많이 쓰인다. 주로 0.5, 0.2 비율값을 사용한다. 대다수의 경우 성능이 개선되는 현상을 보이고 있다.
- Activation
활성화함수는 gredient로 학습시 값의 소실이나 폭주를 막기 위해 사용된다. 대체로 relu를 많이 사용하는 추세이다. 활성화 함수와 가중치 초기화 함수는 적절하게 매칭하여 사용하는 것이 좋다.
- relu와 he초기화 함수, sigmoid/tanh과 xavier함수가 일반적이다. -
- Optimizer
다양한 최적화 함수가 존재한다. 모델에 따라 어느정도 적합한 함수가 존재하나, DNN의 경우 Adam 이 일반적으로 성능이 우수하다. 이 역시 데이터와 다른 변수 조합에 따라 적정한 최적화함수 있으니 학습곡선을 통해 확인해보는 것이 좋다.
딥러닝 모델링시 학습곡선 체크하기
학습이 진행됨에 따라 검증데이터의 loss도 함께 감소되어야 한다.
모델의 성능은 위 변수들의 다양한 조합에 따라 개선되는 경우가 많다.
즉, 데이터가 충분하다면 대부분 성능을 좋게 만들어 낼 수 있다.
아래 2가지 DNN모델 설계 결과를 살펴보자
< 튜닝 전 >
# 1. 모델 변수 설정
batch_size = 64
epochs = 15
input_dim = x_train.shape[1]
# 2. 모델 구성
model = Sequential()
model.add(Dense(input_dim, input_dim=input_dim, kernel_initializer="he_normal"))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(classes, kernel_initializer="glorot_normal"))
model.add(Activation('sigmoid'))
# 3. 모델 학습 설정
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 4. 모델 학습
np.random.seed(42)
hist = model.fit(X_train, Y_train, batch_size = batch_size, epochs = epochs, verbose = 1, validation_split = .2)
위 모델링은 다른 유사 데이터셋에서는 우수한 성능을 나타냈던 설계이다. 하지만 테스트 데이터의 재현율(recall)이 좋지 않은 결과가 나왔다.
교차검증
Trian 검증
accuracy : 1.00 recall : 1.00 precision : 1.00 f1_score: 1.00
Test 검증
accuracy : 0.67 recall : 1.00 precision : 0.60 f1_score: 0.75
Pure 검증
accuracy : 0.57 recall : 0.99 precision : 0.52 f1_score: 0.68
과적합되어 test와 pure데이터의 성능이 매우 좋지 않다. 위에 나열한 변수들을 중점으로 데이터 구조와 학습곡선을 살펴가며 재설계해볼 필요가 있다.
< 튜닝 후 >
모델링
# 1. 모델 변수 설정
batch_size = 64
epochs = 15
input_dim = x_train.shape[1]
# 2. 모델 구성
model = Sequential()
model.add(Dense(512, input_dim=input_dim, kernel_initializer="he_normal"))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(18, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(classes, kernel_initializer="glorot_normal"))
model.add(Activation('sigmoid'))
# 3. 모델 학습 설정
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 4. 모델 학습
np.random.seed(42)
hist = model.fit(X_train, Y_train, batch_size = batch_size, epochs = epochs, verbose = 1, validation_split = .2)
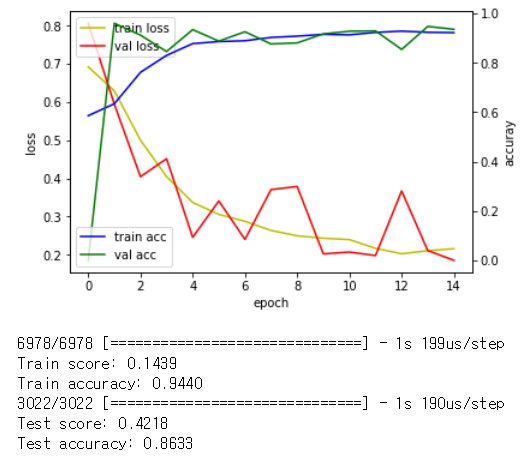
레이어층을 늘리는 대신 점진적으로 노드수를 줄여나가며 Dropout을 적용하였다.
위의 학습곡선을 살펴보면 학습함에 따라 검증데이터의 loss가 줄어들고 있는 것을 확인할 수 있다.
교차검증
Trian 검증
accuracy : 0.96 recall : 0.97 precision : 0.95 f1_score: 0.96
Test 검증
accuracy : 0.85 recall : 0.86 precision : 0.84 f1_score: 0.85
Pure 검증
accuracy : 0.85 recall : 0.92 precision : 0.80 f1_score: 0.86
pure데이터의 리콜성능도 매우 좋아졌다.
딥러닝에서 정확도는 항목수가 충분하면 얼마든지 높게 만들어질 수 있다.
중요한 건 1)검증데이터가 학습함에 따라 loss가 잘 줄어들고 있는지와
2)테스트 데이터의 성능(특히 재현율)을 유의해야 한다.
