* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] 평균회귀를 활용한 Long/Short 전략
By MK on January 26, 2019
평균회귀전략은 자산의 가격이 추세상 안정권에 있고 경향에 따라 무작위로 변동한다는 가정에서 성립된다.
따라서 추세를 벗어나면 방향이 꺽이고 다시 추세로 되돌아가려는 경향 이 있다.
즉, 값이 비정상적으로 높으면 내려갈 것으로 예상하고 비정상적으로 낮으면 다시 올라갈 것으로 예상한다.
사용한 라이브러리
import FinanceDataReader as fdr
fdr.__version__
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
1. Single-stock mean reversion
1) 데이터 가져오기
종목별 시세 데이터를 가져올 수 있으면 된다.
아래 코드는 FinanceDataReader를 사용할때 특정 기간내 종목별 데이터 건수가 상이하여 임시 작업한 케이스이다.
# 한국거래소 상장종목 전체
# 용도 : 코드와 종목명 가져오기
df_krx = fdr.StockListing('KRX')
# 코스피 종목 추출
# 용도 : DataReader 사용시 종목별 기간 조회 건수가 상이하다.
# 코스피 데이터 날짜를 기준으로 가져오기 위해 사용
strt_dt = '2014-01-01' # 시작일 지정
end_dt = '2018-12-31' # 종료일 지정
kospi_df = fdr.DataReader('KS11', strt_dt,end_dt)
kospi_df.reset_index(inplace = True)
def stock_reader(kospi_df, code_list, n=0):
if n == 0:
n = len(code_list)
stock_df = pd.DataFrame()
stock_df['Date'] = kospi_df['Date']
print("동기간 KOSPI 생성일수 : ", len(kospi_df['Date']))
normal_cnt = 0
err_cnt = 0
code_nm_list = []
for code in code_list:
stock = df_krx[df_krx.Symbol == code]
code_nm = list(stock.Name)[0]
try:
temp = fdr.DataReader(code, strt_dt, end_dt)
# 데이터일수가 시장보다 작으면 skip(최근 상장 데이터로 판단)
if len(temp) < len(kospi_df['Date']):
err_cnt += 1
print("skip : (",err_cnt,")", code, code_nm, strt_dt, end_dt, ", 건수 : ", len(temp))
continue
temp.reset_index(inplace = True)
temp_df = pd.merge(temp[['Date','Close']], kospi_df[['Date']], on='Date', how='right')
stock_df[code_nm] = temp_df.Close
normal_cnt += 1
code_nm_list.append(code_nm)
print("정상 : (",normal_cnt,")", code, code_nm, strt_dt, end_dt, ", 건수 : ", len(temp), "->", len(stock_df))
except:
err_cnt += 1
print("skip : (",err_cnt,")", code, code_nm, strt_dt, end_dt, ", 건수 : ", len(temp))
if normal_cnt == n:
print('총', n,'개 생성 설정 / ', normal_cnt, '개 생성 완료')
break # n개 종목 생성시 종료
# 데이터 정렬
stock_df.sort_values('Date', ascending=True, inplace=True) # ascending=True 오름차순, False 내림차순
# 결측치 채우기
stock_df.fillna(method='ffill', inplace=True)
return stock_df, code_nm_list
추출할 종목을 지정
code_list = ['055550']
stock_df, code_nm_list = stock_reader(kospi_df, code_list)
동기간 KOSPI 생성일수 : 1226
정상 : ( 1 ) 055550 신한지주 2014-01-01 2018-12-31 , 건수 : 1375 -> 1226
총 1 개 생성 설정 / 1 개 생성 완료
stock_df.head(3)
| Date | 신한지주 |
|---|---|
| 2014-01-02 | 46600 |
| 2014-01-03 | 44850 |
| 2014-01-06 | 45550 |
2) 그래프 확인
prices = pd.DataFrame(stock_df[code_nm_list[0]])
code_nm = code_nm_list[0]
prices['mu'] = [prices[code_nm][:i].mean() for i in range(len(prices))]
# Plot the price and the moving average
plt.figure(figsize=(15,7))
plt.plot(prices[code_nm])
plt.plot(prices['mu']);
plt.show()
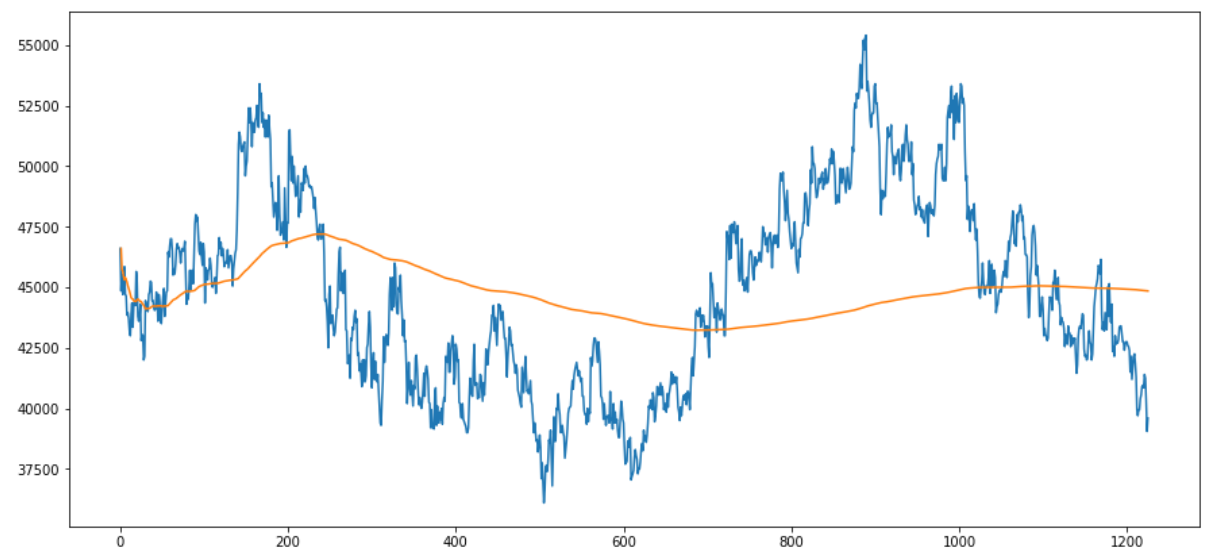
3) Long/Short 전략
z-socre에 따른 전략을 세운다.
1보다 크면 매도, -1보다 작으면 매도
-0,5 ~ 0,5 사이이면 표지션을 정리한다.
zscores = [(prices[code_nm][i] - prices['mu'][i]) / np.std(prices[code_nm][:i]) for i in range(len(prices))]
# Start with no money and no positions
money = 0
count = 0
for i in range(len(prices)):
# Sell short if the z-score is > 1
if zscores[i] > 1:
money += prices[code_nm][i]
count -= 1
# Buy long if the z-score is < 1
elif zscores[i] < -1:
money -= prices[code_nm][i]
count += 1
# Clear positions if the z-score between -.5 and .5
elif abs(zscores[i]) < 0.5:
money += count*prices[code_nm][i]
count = 0
print(money)
시뮬레이션 예상 결과 아래의 수익을 얻을 수 있다.
1,265,700
2. Mean reversion portfolio
여러 종목간 상대적 저평가, 고평가 여부를 산출해 위험을 완화하는 전략을 구사할 수 있다.
1) 데이터 가져오기
n = 10 # 생성할 종목수 지정
df_krx_list = df_krx['Symbol'].head(n*2) # 임시로 2배까지 루프
stock_df, code_nm_list = stock_reader(kospi_df, df_krx_list, n)
동기간 KOSPI 생성일수 : 1226
정상 : ( 1 ) 001040 CJ 2014-01-01 2018-12-31 , 건수 : 1331 -> 1226
정상 : ( 2 ) 011150 CJ씨푸드 2014-01-01 2018-12-31 , 건수 : 1298 -> 1226
정상 : ( 3 ) 082740 HSD엔진 2014-01-01 2018-12-31 , 건수 : 1305 -> 1226
정상 : ( 4 ) 001390 KG케미칼 2014-01-01 2018-12-31 , 건수 : 1313 -> 1226
정상 : ( 5 ) 010060 OCI 2014-01-01 2018-12-31 , 건수 : 1434 -> 1226
정상 : ( 6 ) 002360 SH에너지화학 2014-01-01 2018-12-31 , 건수 : 1410 -> 1226
정상 : ( 7 ) 001740 SK네트웍스 2014-01-01 2018-12-31 , 건수 : 1395 -> 1226
skip : ( 1 ) 285130 SK케미칼 2014-01-01 2018-12-31 , 건수 : 264
skip : ( 2 ) 011810 STX 2014-01-01 2018-12-31 , 건수 : 916
정상 : ( 8 ) 024070 WISCOM 2014-01-01 2018-12-31 , 건수 : 1233 -> 1226
정상 : ( 9 ) 011420 갤럭시아에스엠 2014-01-01 2018-12-31 , 건수 : 1298 -> 1226
skip : ( 3 ) 267290 경동도시가스 2014-01-01 2018-12-31 , 건수 : 402
정상 : ( 10 ) 002240 고려제강 2014-01-01 2018-12-31 , 건수 : 1258 -> 1226
총 10 개 생성 설정 / 10 개 생성 완료
stock_df.set_index('Date', inplace=True)
data = stock_df
data.head(3)
| Date | CJ | CJ씨푸드 | HSD엔진 | KG케미칼 | OCI | SH에너지화학 | SK네트웍스 | WISCOM | 갤럭시아에스엠 | 고려제강 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2014-01-02 | 117500 | 2415 | 8480.0 | 16550 | 188500 | 720 | 7400 | 4925 | 1940 | 30666 |
| 2014-01-03 | 117000 | 2425 | 8270.0 | 17000 | 195000 | 737 | 7460 | 4900 | 1940 | 30332 |
| 2014-01-06 | 115500 | 2410 | 8220.0 | 17400 | 195000 | 745 | 7270 | 4900 | 1990 | 30166 |
2) 첫주 수익률 VS 이후 한달 수익률
data = np.array(data)
# 첫 주의 수익률
wreturns = (data[4] - data[0])/data[0] # 4일 = 1 weak
# Rank
order = wreturns.argsort()
ranks = order.argsort()
# 첫 주 이후, 한달 수익률
mreturns = (data[5+4*4] - data[5])/data[5] # 첫주이후 5day, 한달 후 5일 + 4day*4weak
order2 = mreturns.argsort()
ranks2 = order2.argsort()
# Plot (가로 : 첫주 수익률, 세로 : 첫주 이후 한달 수익률)
plt.figure(figsize=(15,7))
plt.scatter(wreturns, mreturns)
plt.xlabel('Returns for the first week')
plt.ylabel('Returns for the following month')
아래 그래프는 시작하는 첫주의 수익률(가로)과 그에 뒤따르는 한달 수익률(세로)의 관계를 나타낸다. 이는 반비례하는 것처럼 보인다.
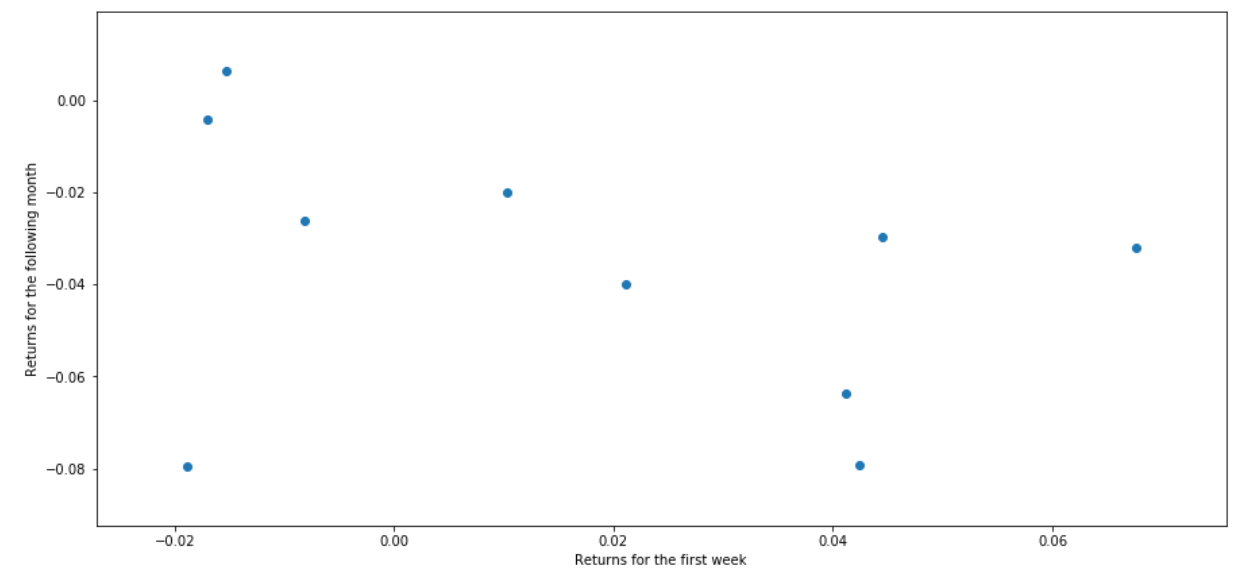
좌측상단에 있을수록 첫주 수익률(가로)이 낮을 때 따르는 한달의 수익률(세로)이 높은 것을 의미한다.
3) Long/Short 전략
지난 주 수익률을 조사한 후 평균회귀전략을 따른다고 가정한다면 어떻게 활용할 수 있을까?
# 비교할 종목간 첫주 수익률 기준으로 랭킹 top 20%, bottom 20%를 찾는다.
# ranks는 첫주 수익률 순위를 의미(낮을 수록 1, 낮은걸 long한다.)
# ranks는 첫주 이후 한달 수익률 순위를 의미
top_cnt = int(len(ranks) * 0.2)
bottom_cnt = int(len(ranks) * 0.8)
longs = np.array([int(x < top_cnt)for x in ranks])
shorts = np.array([int(x >= bottom_cnt) for x in ranks])
print('Going long in:', [code_nm_list[i] for i in range(len(code_nm_list)) if longs[i]])
print('Going short in:', [code_nm_list[i] for i in range(len(code_nm_list)) if shorts[i]])
# Resolve all positions and calculate how much we would have earned
print('Yield:', sum((data[-1] - data[4])*(longs - shorts)))
Going long in: ['CJ', 'HSD엔진']
Going short in: ['SH에너지화학', 'SK네트웍스']
Yield: 5,312.0
Long 포지션으로 'CJ', 'HSD엔진',
Short 포지션으로 'SH에너지화학', 'SK네트웍스'가 산출되었다.
시뮬레이션 결과 예상수익은 5,312 이다.
이 밖에, Pair trading을 하기 위해 두 증권간의 거리를 공적분 검증하여 활용할 수 있다.공적분이 성립될 경우 두 주식은 일반적으로 시장과 산업변화 내에서 함께 움직이며 상대적으로 움직이지 않는다.
두 주식의 거리가 멀어지면 평균 회귀에 의해 다시 가까워질 것으로 예상하고 매매전략에 활용한다. 즉 z-score가 -1 이하이면 예상보다 가깝고, 1 이상이면 예상보다 멀다고 생각할 수 있다.
공적분을 활용한 두 주식의 Pair Trading은 아래 게시글에서 확인할 수 있다.
[이전포스팅] 공적분을 활용한 Pair Trading 보러가기
Reference
https://medium.com/auquan/mean-reversion-simple-trading-strategies-part-1-a18a87c1196a
