* 본 포스트는 개인연구/학습 기록 용도로 작성되고 있습니다.
[Python] 산업 전이행렬 만들기
By MK on January 1, 2019
글로벌 변동성이 커지고 각종 경기지표가 악화됨에 따라 신용리스크가 가중되고 있다.
산업 및 기업의 신용리스크 확인시 등급전이행렬을 확인하는 것은 매우 유용하다.
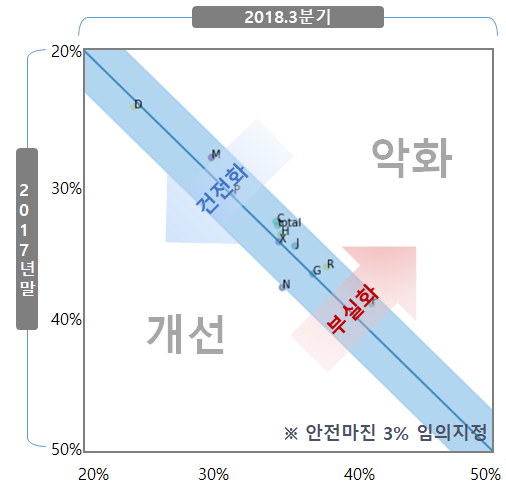
전이행렬을 통해 우상향할수록 위험이 악화되고, 좌하향할수록 위험이 개선되는 것을 확인할 수 있다.
보통의 신용등급 전이행렬에서는 현재 등급에서 1년후 특정 등급으로 이동할 확률을 나타내는데 쓰인다.
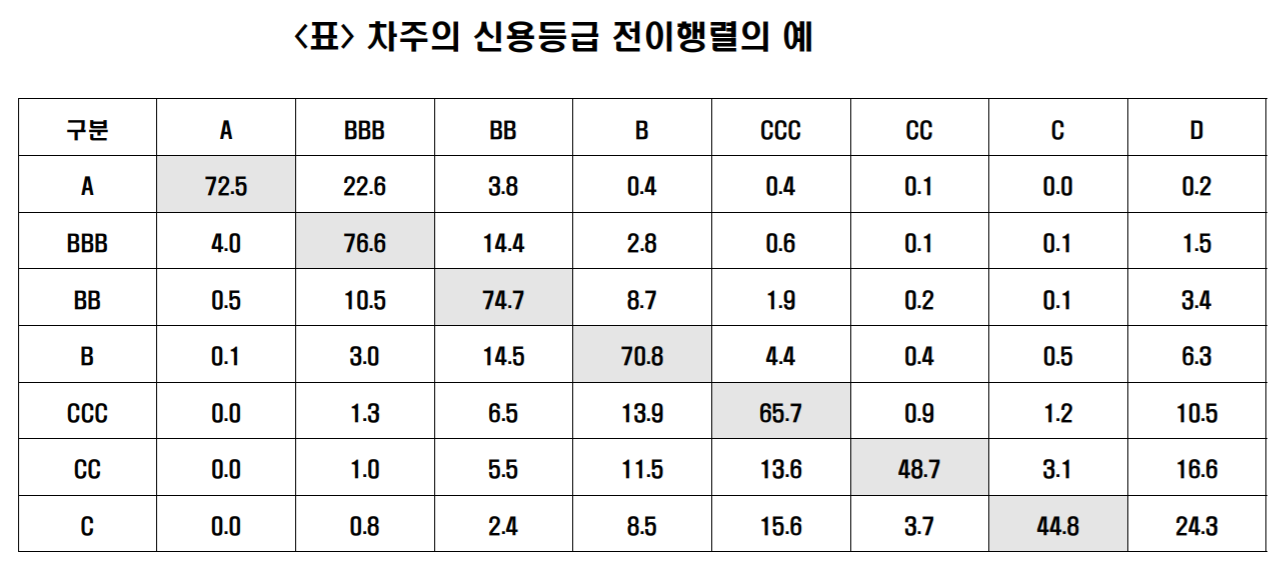
위의 표에 따르면 BBB등급의 차주가 1년 후 A등급으로 전환할 확률은 4%이다.
다른 예로 직전(주로 1년 전) 등급과 현재 등급의 변화를 나타낼때도 유용하게 사용될 수 있다.
후자의 개념을 적용하여 산출한 산업별 위험이 전년 대비해서 어떻게 변화하는지확인해보고자 한다.
개념만을 차용해 등급 대신 위험 확률 값을 넣고 그래프로 표현할 예정이다.
1. 데이터 가져오기
data = pd.read_csv("./datas/industry_matrix.csv", encoding='euc-kr')
아래와 같은 포맷이다.
| industry | id | count | 2013 | 2014 | 2015 | 2016 | 2017 | 2018Q3 |
|---|---|---|---|---|---|---|---|---|
| 총합계 | total | 1923 | 31.62105 | 30.61511 | 32.4839 | 30.36369 | 33.21931 | 34.33319 |
| 제조업 | C | 1252 | 30.42722 | 30.00786 | 32.02782 | 30.03699 | 32.91973 | 34.20605 |
| 출판 영상 방송통신 및 정보서비스업 | J | 212 | 33.89064 | 30.78209 | 32.52728 | 30.3001 | 34.74163 | 35.58819 |
| 전문 과학 및 기술 서비스업 | M | 158 | 27.30578 | 26.60527 | 28.37879 | 26.98155 | 28.1938 | 29.53939 |
| 도매 및 소매업 | G | 134 | 35.71608 | 34.36381 | 36.09455 | 34.3897 | 36.81342 | 36.87577 |
| 건설업 | F | 64 | 43.71257 | 41.87939 | 43.20357 | 36.2027 | 39.01434 | 41.14245 |
| 운수업 | H | 27 | 38.27187 | 31.83501 | 35.3135 | 32.19269 | 33.86897 | 34.55875 |
| 기타 | X | 23 | 34.41969 | 34.41969 | 34.41969 | 34.41969 | 34.41969 | 34.41969 |
| 사업시설관리 및 사업지원 서비스업 | N | 17 | 30.5455 | 27.7833 | 29.05953 | 30.96413 | 37.81404 | 34.66609 |
| 예술 스포츠 및 여가관련 서비스업 | R | 12 | 39.50355 | 35.40623 | 35.20804 | 36.09189 | 36.28727 | 37.88297 |
| 교육 서비스업 | P | 11 | 30.2441 | 26.0048 | 30.97068 | 30.01419 | 30.82166 | 31.08653 |
| 전기 가스 증기 및 수도사업 | D | 10 | 24.21352 | 24.14289 | 24.66476 | 24.2788 | 24.44411 | 23.91144 |
실제 데이터는 2개년만 선택하여 사용하게 된다.
2. 그래프 축 만들기
max = 50
min = 20
x1 = list(range(min,max+1))
y1 = list(range(max-min,-1,-1))
len(x1), len(y1)
plot_data = pd.DataFrame()
plot_data['x1'] = x1
plot_data['y1'] = y1
min, max는 위험값의 최대 최소 범위를 나타낼 수 있는 구간이다.
결과는 아래와 같이 생성된다.
| x1 | y1 | |
|---|---|---|
| 0 | 20 | 30 |
| 1 | 19 | 31 |
| 2 | 18 | 32 |
| 3 | 17 | 33 |
| 4 | 16 | 34 |
| 5 | 15 | 35 |
| 6 | 14 | 36 |
| 7 | 13 | 37 |
| 8 | 12 | 38 |
| 9 | 11 | 39 |
| 10 | 10 | 40 |
| 11 | 9 | 41 |
| 12 | 8 | 42 |
| 13 | 7 | 43 |
| 14 | 6 | 44 |
| 15 | 5 | 45 |
| 16 | 4 | 46 |
| 17 | 3 | 47 |
| 18 | 2 | 48 |
| 19 | 1 | 49 |
| 20 | 0 | 50 |
3. 그래프 생성하기
data와 plot_data 설정이 완료됐으면 그래프를 그릴 차례이다.
import matplotlib.pyplot as plt
import numpy as np
max_value = max
min_value = 0
error = 3# % 밴드(안전마진) 설정
# create data
x = data['2018Q3']
tmp_y = data['2017']
y = max_value-tmp_y
# 랜덤 컬러 지정
colors = np.random.rand(len(data))
plt.scatter(x, y,c=colors, alpha=0.5)
plt.plot(plot_data.x1,plot_data.y1)
# 라벨 만들기
def label_point(x, y, val, ax):
a = pd.concat({'x': x, 'y': y, 'val': val}, axis=1)
for i, point in a.iterrows():
ax.text(point['x']+.02, point['y'], str(point['val']))
label_point(x, y, data.id, plt.gca())
plt.xlim(min,max)
plt.ylim(0,max-min)
x1 = plot_data['x1'].map(lambda x: float(x))
y1 = plot_data['y1'].map(lambda x: float(x))
plt.fill_between(x1, y1-error, y1+error,alpha=0.5, edgecolor='#66aee3', facecolor='#66aee3')
fig = plt.gcf() #현재 figure에 불러오기
fig.set_size_inches(7,7) #크기 바꾸기(inch 단위)
plt.show()
안전마진은 error 값을 임의로 3% 셋팅하고 edgecolor='#66aee3'로 밴드 색상을 푸른색으로 지정하였다.
아래와 같은 그래프를 얻을 수 있다.
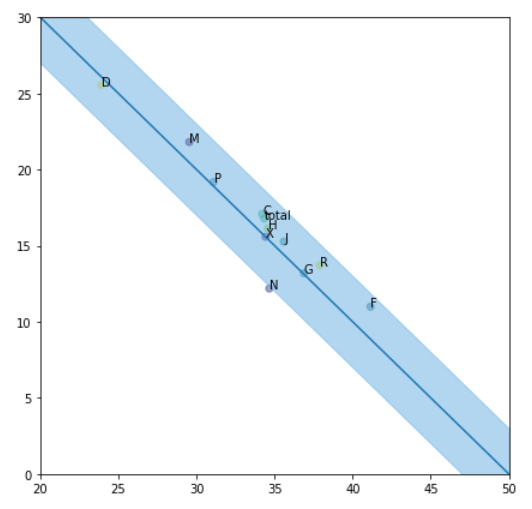
가로축이 현재의 위험확률 세로축이 과거의 위험확률이므로 우상향할수록 악화되며 좌하향할수록 개선됨을 의미한다.
확률값 해석시에 세로축을 유의해야 한다. 그래프 가독성을 쉽게 하기 위해 세로축은 반전시킨 확률이다. 즉 아래와 같이 변경해서 해석해야 한다.